classMultiHeadAttention(nn.Module): def__init__(self, h, d_model, dropout_prob=0.1): """ Args: h: number of heads d_model: dimension of the vector for each token in input and output dropout_prob: probability of dropout """ super().__init__() self.head_dim = d_model // h self.num_heads = h # W_Q, W_K, W_V, W_O self.linears = nn.ModuleList([nn.Linear(d_model, d_model) for _ inrange(4)]) self.dropout = nn.Dropout(dropout_prob) defforward(self, query, key, value, mask=None): """ Args: query: (batch_size, seq_len_q, d_model) key: (batch_size, seq_len_k, d_model) value: (batch_size, seq_len_v, d_model), seq_len_k == seq_len_v mask: Returns: output: (batch_size, seq_len_q, d_model) attn: (batch_size, num_heads, seq_len_q, seq_len_k) """ if mask isnotNone: mask = mask.unsqueeze(1) n_batches = query.size(0) # 1. linear projection for query, key, value # after this step, the shape of each is (batch_size, num_head, seq_len, head_dim) # -1维度其实就是seq_len,只是Q、K、V的seq_len可能不一样 query, key, value = [linear(x).view(n_batches, -1, self.num_heads, self.head_dim).transpose(1,2) for linear, x inzip(self.linears, (query, key, value))] # 2. scaled dot product attention # out: (batch_size, num_head, seq_len_q, head_dim) out, _ = scaled_dot_product_attention(query, key, value, mask, self.dropout) # 3. "Concat" using a view and apply a final linear out = ( out.transpose(1, 2).contiguous().view(n_batches, -1, self.num_heads * self.head_dim) ) out = self.linears[3](out) del query, key, value return out
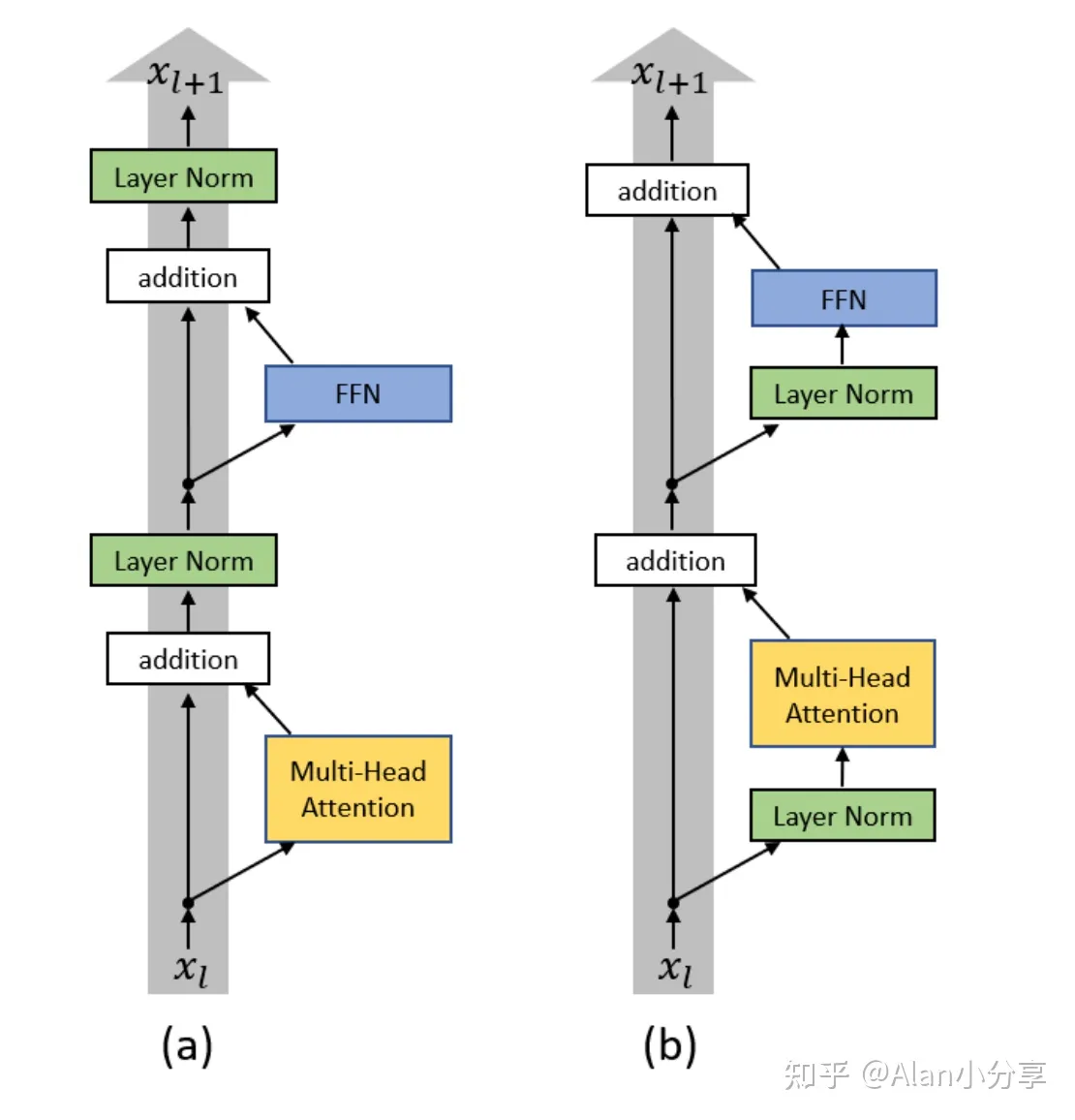
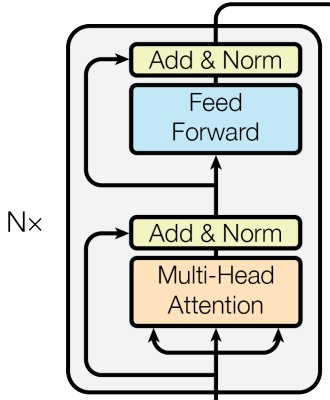
classSubLayer(nn.Module): """ Do pre-layer normalization for input, and then run multi-head attention or feed forward, and finally do the residual connection. """ def__init__(self, d_model, dropout_prob=0.1): super.__init__() self.norm = LayerNorm(d_model) self.dropout = nn.Dropout(dropout_prob) defforward(self, x, main_logic): # main_logic是Multi-Head Attention或者FeedForward x_norm = self.norm(x) return x + self.dropout(main_logic(x_norm))
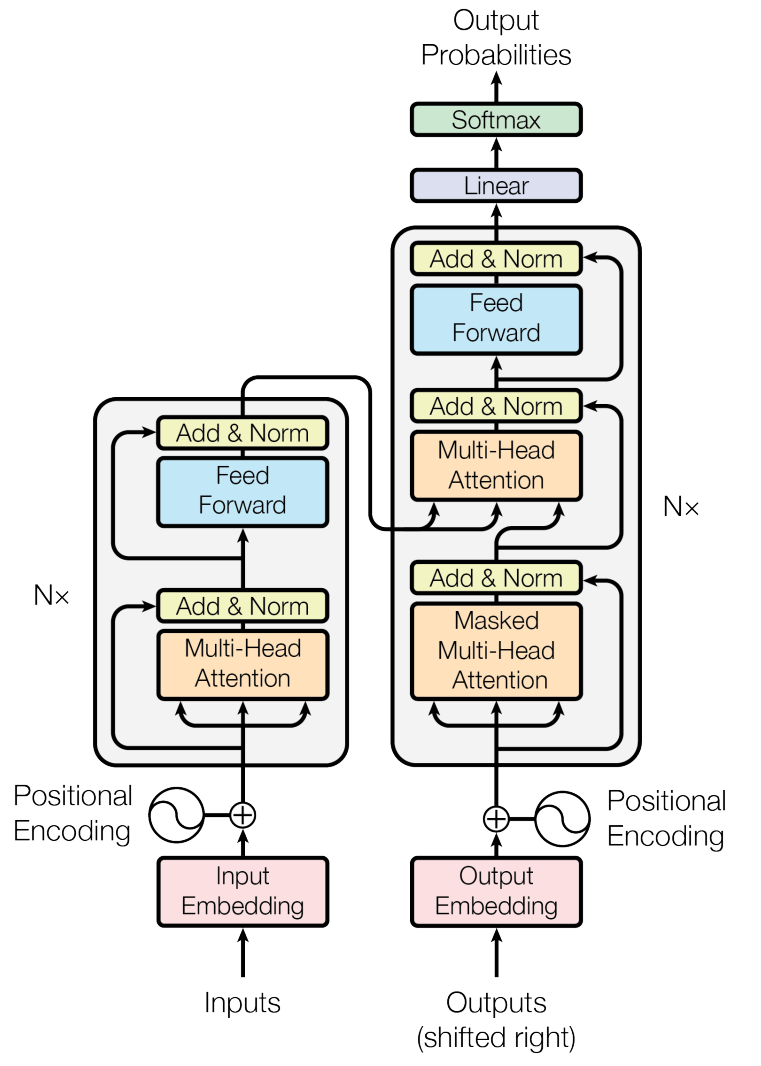
classEncoder(nn.Module): def__init__(self, d_model, N, heads): super.__init__() self.N = N self.layers = nn.ModuleList([copy.deepcopy(EncoderLayer(d_model, heads)) for i inrange(N)]) self.norm = LayerNorm(d_model) defforward(self, x, mask): for i inrange(self.N): x = self.layers[i](x, mask) return self.norm(x)
Decoder
Decoder可以复用上边的模块,因此只需要写一个DecoderLayer和Decoder就行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classDecoderLayer(nn.Module): """ Decoder is made of self-attn, src-attn, and feed forward. """ def__init__(self, d_model, heads, d_ff = 2048, dropout_prob = 0.1): super().__init__() self.self_atten = MultiHeadAttention(heads, d_model, dropout_prob=dropout_prob) self.src_atten = MultiHeadAttention(heads, d_model, dropout_prob=dropout_prob) self.ffn = FeedForward(d_model, d_ff, dropout_prob=dropout_prob) self.sublayers = nn.ModuleList([SubLayer(d_model, dropout_prob) for _ inrange(3)]) defforward(self, x, memory, src_mask, tgt_mask): x = self.sublayers[0](x, lambda x: self.self_atten(x, x, x, tgt_mask)) x = self.sublayers[1](x, lambda x: self.src_atten(x, memory, memory, src_mask)) x = self.sublayers[2](x, self.ffn) return x
1 2 3 4 5 6 7 8 9 10
classDecoder(nn.Module): def__init__(self, d_model, N, heads): self.N = N self.layers = nn.ModuleList([copy.deepcopy(DecoderLayer(d_model, heads)) for i inrange(N)]) self.norm = LayerNorm(d_model) defforward(self, x, memory, src_mask, tgt_mask): for layer in self.layers: x = layer(x, memory, src_mask, tgt_mask) return self.norm(x)
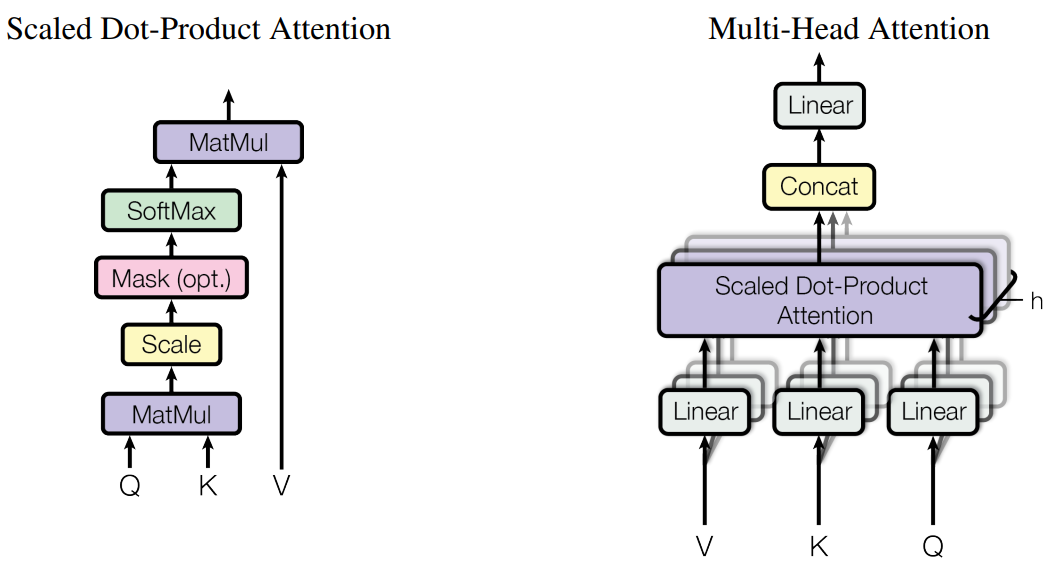
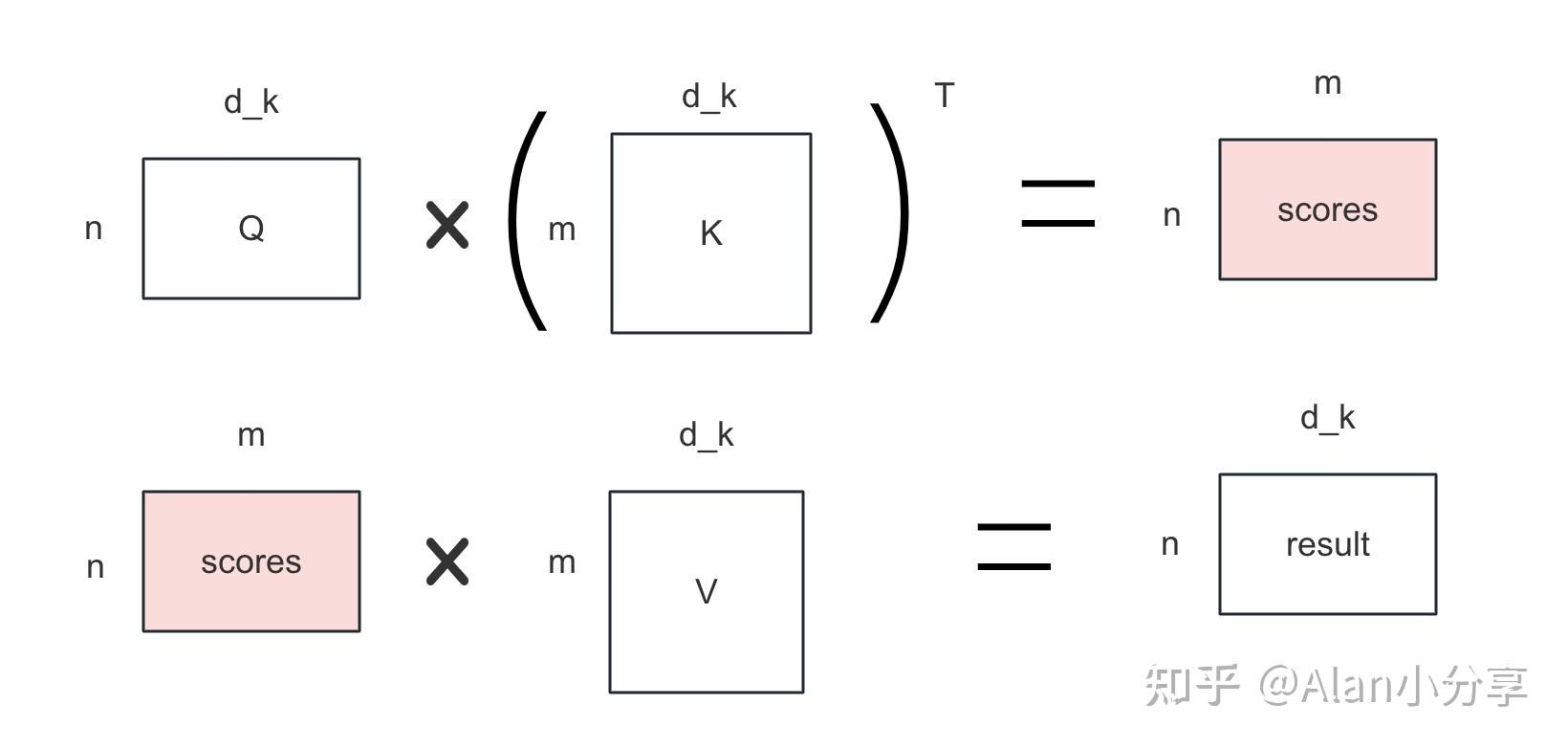

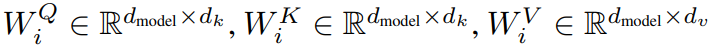
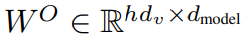
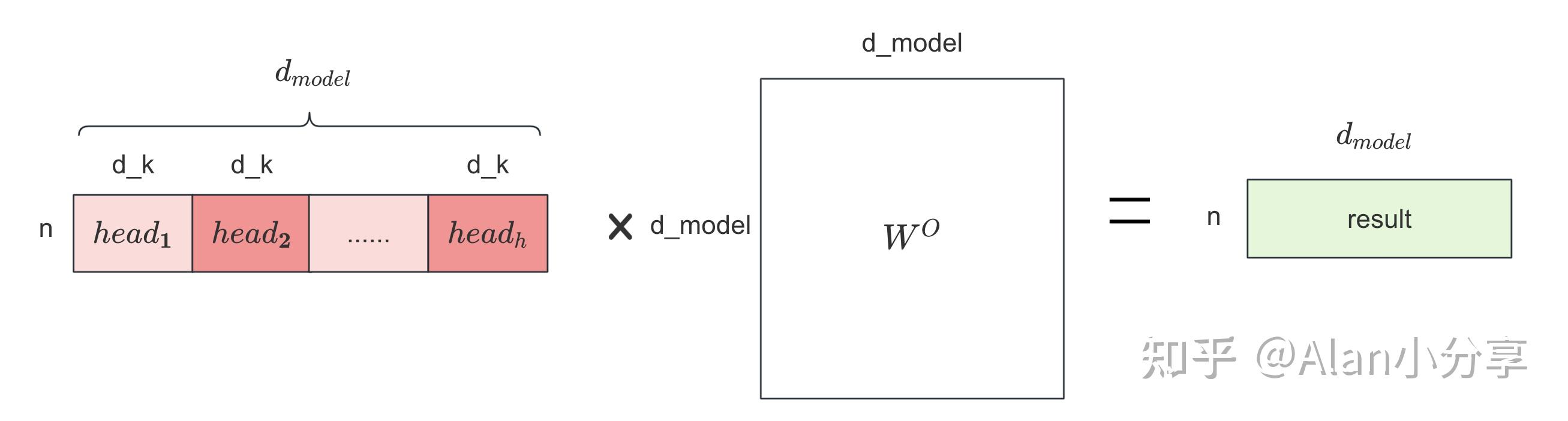
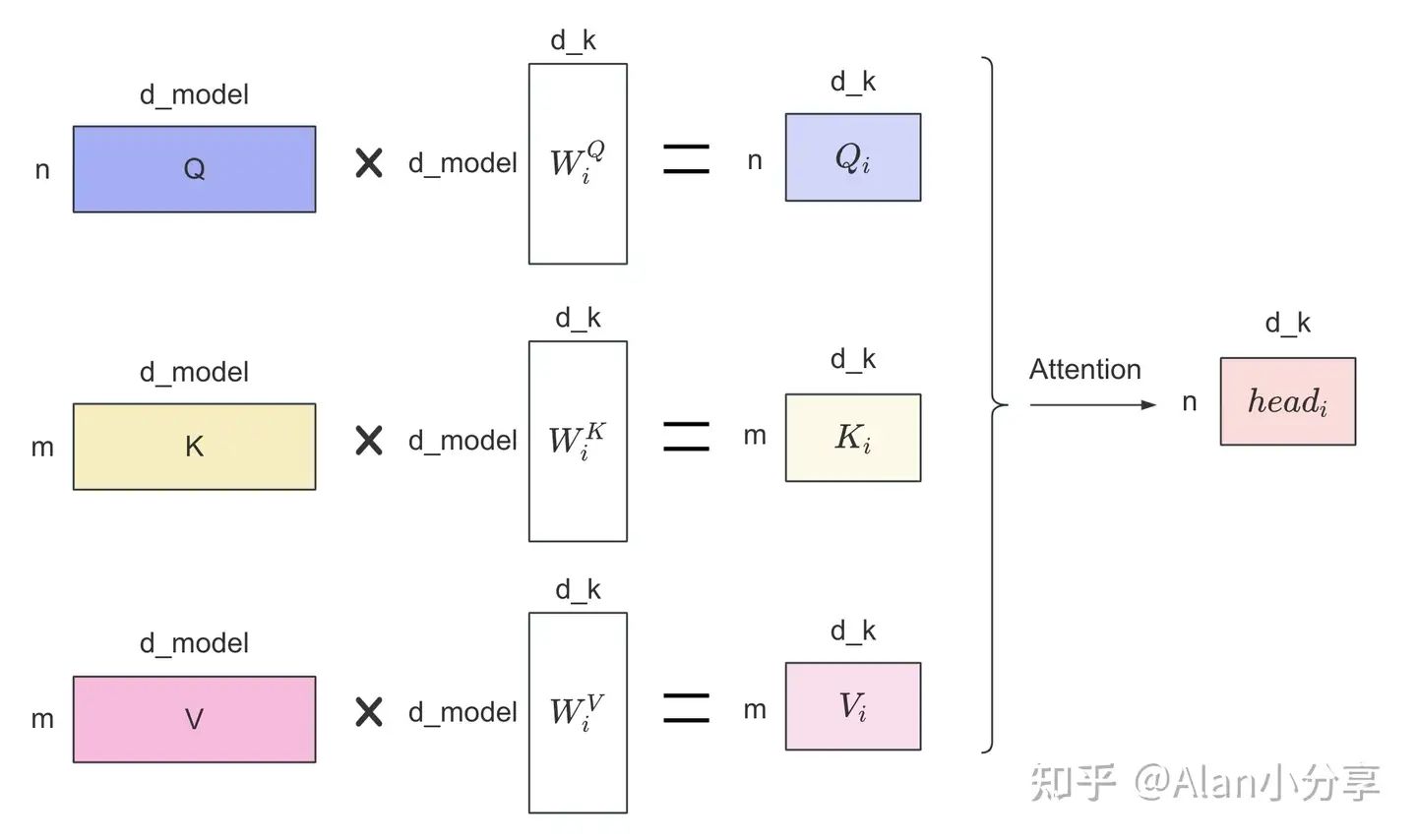 然后拼接,再做一次线性操作:
然后拼接,再做一次线性操作: