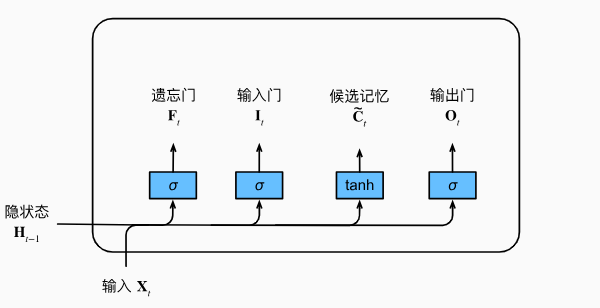
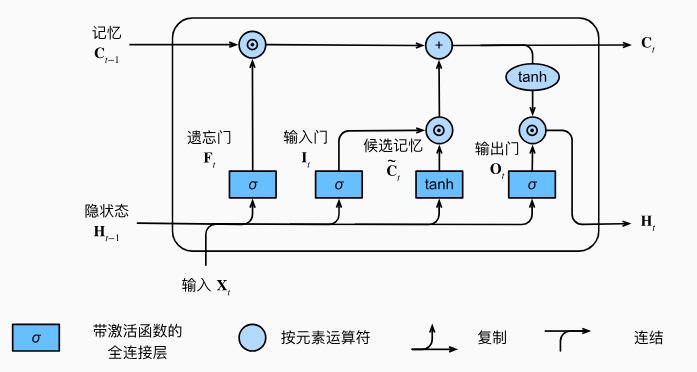
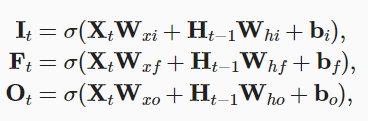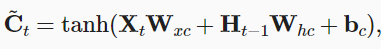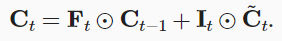classLSTM(Module): def__init__(self, input_size, hidden_size, num_layers=1, bias=True, device=None, dtype="float32"): super().__init__() """ Applies a multi-layer long short-term memory (LSTM) RNN to an input sequence. Parameters: input_size - The number of expected features in the input x hidden_size - The number of features in the hidden state h num_layers - Number of recurrent layers. bias - If False, then the layer does not use bias weights. Variables: lstm_cells[k].W_ih: The learnable input-hidden weights of the k-th layer, of shape (input_size, 4*hidden_size) for k=0. Otherwise the shape is (hidden_size, 4*hidden_size). lstm_cells[k].W_hh: The learnable hidden-hidden weights of the k-th layer, of shape (hidden_size, 4*hidden_size). lstm_cells[k].bias_ih: The learnable input-hidden bias of the k-th layer, of shape (4*hidden_size,). lstm_cells[k].bias_hh: The learnable hidden-hidden bias of the k-th layer, of shape (4*hidden_size,). """ self.hidden_size = hidden_size self.num_layers = num_layers self.device = device self.dtype = dtype self.lstm_cells = [LSTMCell(input_size, hidden_size, bias=bias, device=device, dtype=dtype)] + \ [LSTMCell(hidden_size, hidden_size, bias=bias, device=device, dtype=dtype) for _ inrange(num_layers-1)] defforward(self, X, h=None): """ Inputs: X, h X of shape (seq_len, bs, input_size) containing the features of the input sequence. h, tuple of (h0, c0) with h_0 of shape (num_layers, bs, hidden_size) containing the initial hidden state for each element in the batch. Defaults to zeros if not provided. c0 of shape (num_layers, bs, hidden_size) containing the initial hidden cell state for each element in the batch. Defaults to zeros if not provided. Outputs: (output, (h_n, c_n)) output of shape (seq_len, bs, hidden_size) containing the output features (h_t) from the last layer of the LSTM, for each t. tuple of (h_n, c_n) with h_n of shape (num_layers, bs, hidden_size) containing the final hidden state for each element in the batch. h_n of shape (num_layers, bs, hidden_size) containing the final hidden cell state for each element in the batch. """ batch_size = X.shape[1] if h isNone: h0 = [init.zeros(batch_size, self.hidden_size, device=self.device, dtype=self.dtype) for _ inrange(self.num_layers)] c0 = [init.zeros(batch_size, self.hidden_size, device=self.device, dtype=self.dtype) for _ inrange(self.num_layers)] else: h0, c0 = h h0 = tuple(ops.split(h0, axis=0)) c0 = tuple(ops.split(c0, axis=0)) h_n = [] c_n = [] inputs = list(ops.split(X, axis=0)) for layer, h, c inzip(self.lstm_cells, h0, c0): for t, inputinenumerate(inputs): h, c = layer(input, (h, c)) inputs[t] = h h_n.append(h) c_n.append(c) return ops.stack(inputs, axis=0), (ops.stack(h_n, axis=0), ops.stack(c_n, axis=0))
classLanguageModel(nn.Module): def__init__(self, embedding_size, output_size, hidden_size, num_layers=1, seq_model='rnn', device=None, dtype="float32"): """ Consists of an embedding layer, a sequence model (either RNN or LSTM), and a linear layer. Parameters: output_size: Size of dictionary embedding_size: Size of embeddings hidden_size: The number of features in the hidden state of LSTM or RNN seq_model: 'rnn' or 'lstm', whether to use RNN or LSTM num_layers: Number of layers in RNN or LSTM """ self.hidden_size = hidden_size super(LanguageModel, self).__init__() self.embedding = nn.Embedding(output_size, embedding_size, device=device, dtype=dtype) if seq_model == 'rnn': self.seq_model = nn.RNN(embedding_size, hidden_size, num_layers=num_layers, device=device, dtype=dtype) elif seq_model == 'lstm': self.seq_model = nn.LSTM(embedding_size, hidden_size, num_layers=num_layers, device=device, dtype=dtype) self.linear = nn.Linear(hidden_size, output_size, device=device, dtype=dtype)
defforward(self, x, h=None): """ Given sequence (and the previous hidden state if given), returns probabilities of next word (along with the last hidden state from the sequence model). Inputs: x of shape (seq_len, bs) h of shape (num_layers, bs, hidden_size) if using RNN, else h is tuple of (h0, c0), each of shape (num_layers, bs, hidden_size) Returns (out, h) out of shape (seq_len*bs, output_size) h of shape (num_layers, bs, hidden_size) if using RNN, else h is tuple of (h0, c0), each of shape (num_layers, bs, hidden_size) """ seq_len, bs = x.shape x_embedding = self.embedding(x) out, h = self.seq_model(x_embedding, h) out = out.reshape((seq_len*bs, self.hidden_size)) #flatten out = self.linear(out) return out, h