cmu10-414 HW2总结
cmu10-414知识点总结(HW2)
重要代码块
HW2分支的代码结构如下
inin.py
__inin__.py中定义needle对外暴露的模块、类、函数
1 | from . import ops |
第一二行含义,可以通过needle.ops.summation或者needle.summation调用summation函数
optim.py
定义了一些待实现的优化器
autograd.py
定义了Op、Value、Tensor核心数据结构
对于TensorOp,它继承了Op,有3个重要函数(属性)
1 | def compute(self, *args: Tuple[NDArray]): |
输入输出都是array
1 | def gradient( |
输入输出实际都是Tensor。计算这个op对input的偏导数
1 | def __call__(self, *args): |
1 | def make_from_op(op: Op, inputs: List["Value"]): |
__call__函数可以将一个对象当成一个函数使用,当使用“summation”计算a某些维度上的和时,
先通过Summation(axes)(a)创建一个对象,并传入参数a。此时将对象当作函数使用,调用__call__。在make_from_op中创建一个新的tensor,并将其op和input设置为Summation和a。通过realize_cached_data()中调用op.compute()来计算其cached_data
对于Value类,关注其属性
1 | class Value: |
inputs是计算节点的输入,最多是2个
cached_data是这个计算节点将inputs通过op计算后的结果
requires_grad是否需要梯度,因为常数值不需要计算梯度
对于Tensor类,新增了grad: "Tensor"属性(注意梯度也是Tensor类型),关注其函数
首先是__init__(),当使用Tensor([2,3,4])初始化时调用该函数。make_from_op()的用法上文说过。
A.data的作用是创建一个和A的cached_data一样的Tensor,但是不具有A的op、inputs等计算图中的关系,即独立于A所在的计算图。@data.setter的作用是当设置修改data的数据时调用这个函数,直接将A.cache_data设置为value.cache_data 。
即A.data = A.data + B.data的流程是:
- A和B分别调用detach()创建一个与之cached_data一致的独立于计算图的无梯度Tensor
- 二者相加(Tensor类对一些基本的运算做了重载,后文说明)
- 因为这里要修改data的值,因此调用setter下的函数,将A的cached_data设置为相加后的Tensor的cached_data
设置这样的一个属性的目的是:
假如我们要计算多轮迭代之后的一个Tensor的梯度。只要最后的结果
grad = ndl.Tensor([1, 1, 1], dtype=”float32”)
lr = 0.1
for i in range(5):
w = w + (-lr) * grad
上边写法会在多轮的”+”构建一个计算图,占用很大存储空间,但是我们只要最后的结果。
而用上data属性后,如下的计算方式无需创建额外的Tensor
for i in range(5):
w.data = w.data + (-lr) * grad.data
1 | #将方法转换成属性,通过.data返问 |
当要进行反向传播时,通过backward函数计算计算图中节点梯度。使用方式A.backward()。
在backward中调用compute_gradient_of_variables()函数,先通过find_topo_sort()使用拓扑排序计算由output_tensor结束的计算图的拓扑排序结果,进行reversed的目的是我们计算梯度的过程是从后往前算的
ops->ops_mathematic.py
实现了一些算子类的前向计算与梯度计算,继承自TensorOp
ops->ops_logarithmatic.py
init->init_initializers.py
定义了几个权重的初始化类,用于初始化权重
归一化(Normalization)与正则化(Regularization)
归一化是特征缩放的一种形式,是把数据压缩到一个区间内,比如[0,1]。本节有BatchNorm和LayerNorm。
正则化是为了解决过拟合问题。有L2正则化和L1正则化。权重的大小会影响训练的复杂性。因此可以,使大的权重小一点。
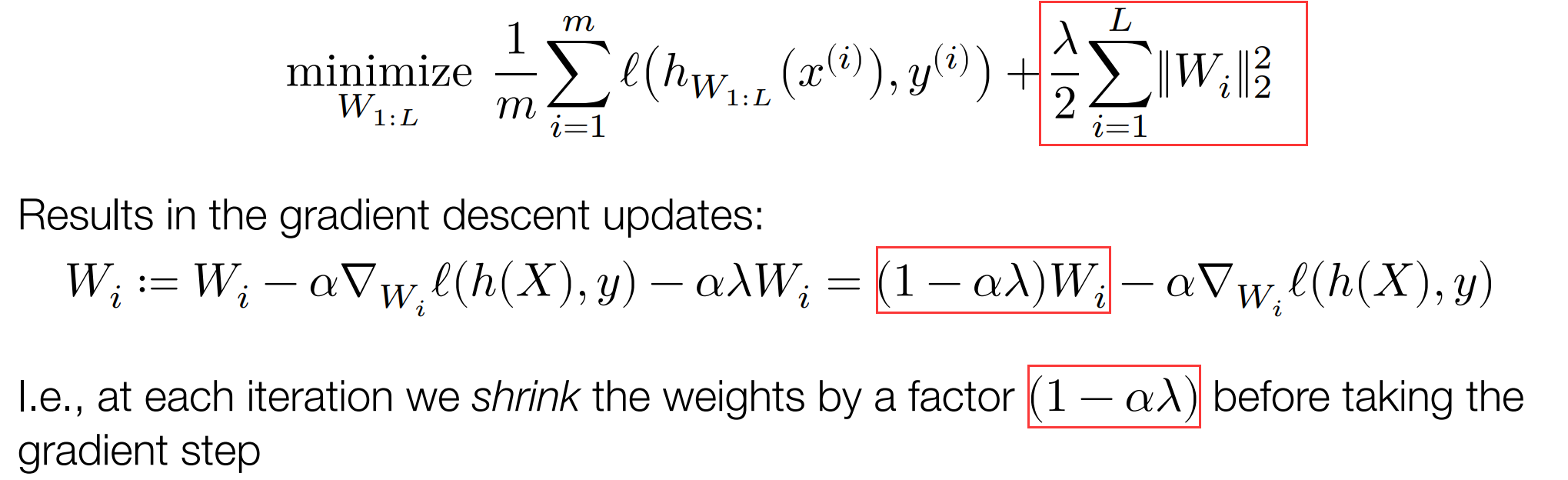
如图L2正则化修改优化的目标函数,使在计算梯度前先将权重进行收缩