梳理cuda算子编译与python调用的流程
梳理cuda算子编译与python调用的流程
跟踪vllm在generation阶段的代码,发现其page_atttention有V1和V2两个版本。以其V2版本为例。
下图是他在vllm/_custom_ops.py中的定义,调用vllm_ops中的paged_attention_v2。但是这个paged_attention_v2在那里呢。
通过vscode全局搜索paged_attention_v2,发现其是cuda实现的。那么为什么这里在py文件中可以直接调用呢?
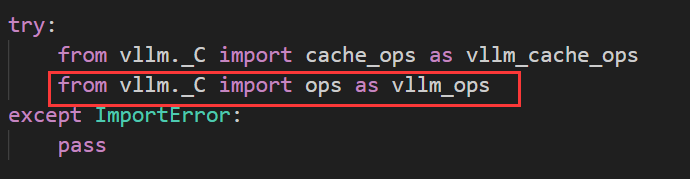
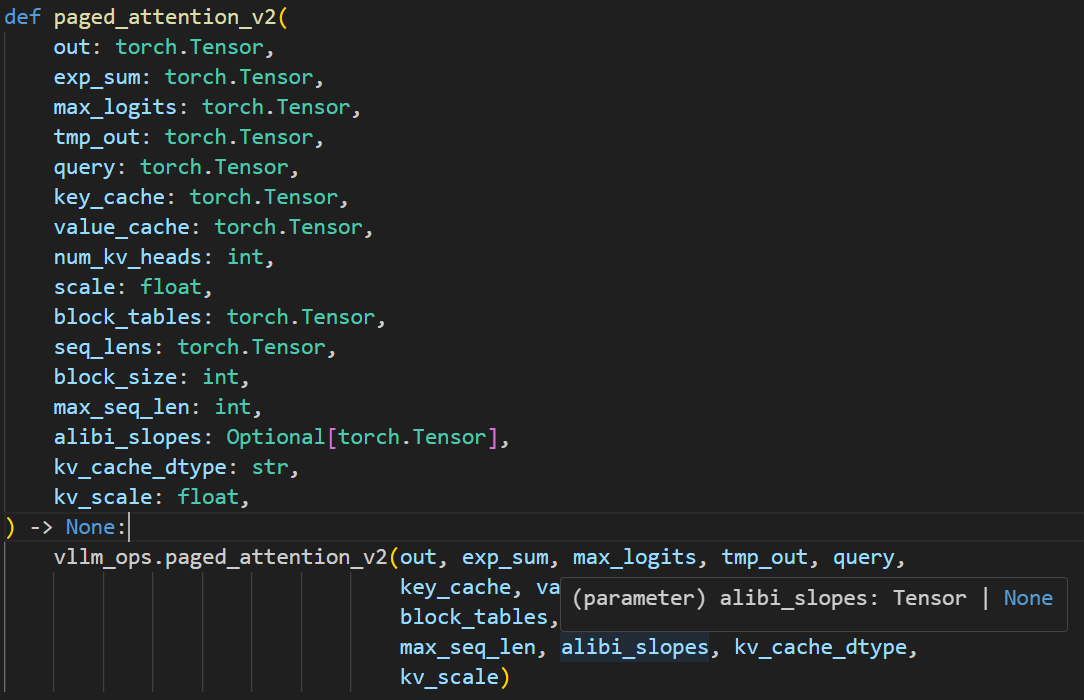
参考https://blog.csdn.net/u011590738/article/details/135999385文章。弄明白了其原理。
遂做记录
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 欢迎来到酷狗的个人博客!