首先,还是给出参考文献:参考博客
每CPU页框高速缓存 因为内存经常请求单个页框,因此为了提升性能,在伙伴系统之外又定义了一个per-CPU高速缓存
1 2 3 4 struct zone { struct per_cpu_pages __percpu *per_cpu_pageset ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct per_cpu_pages { int count; int high; int batch; short free_factor; #ifdef CONFIG_NUMA short expire; #endif struct list_head lists [NR_PCP_LISTS ]; };
其中的NR_PCP_LISTS被定义为
1 2 3 4 5 6 #define NR_PCP_LISTS (MIGRATE_PCPTYPES * (PAGE_ALLOC_COSTLY_ORDER + 1 + NR_PCP_THP))
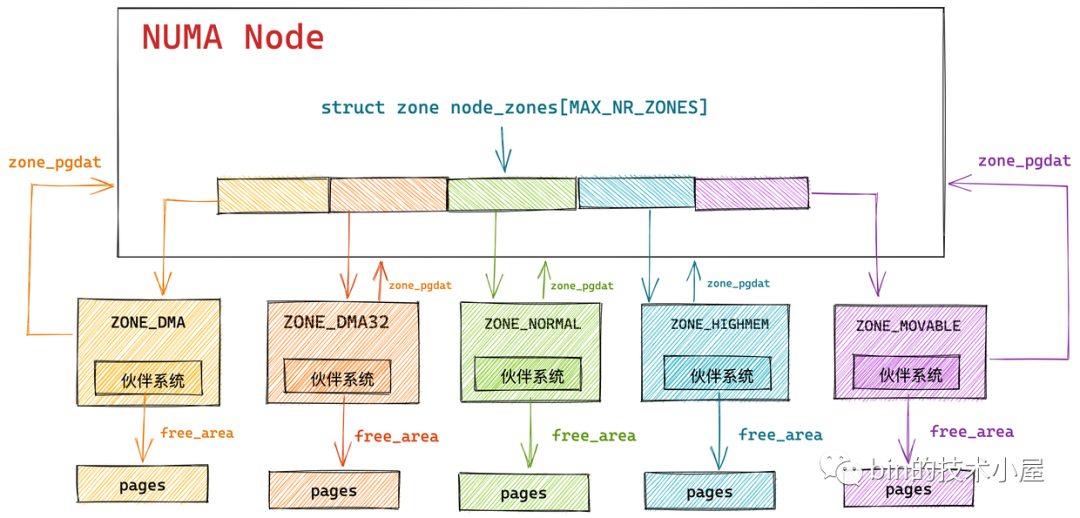
伙伴系统
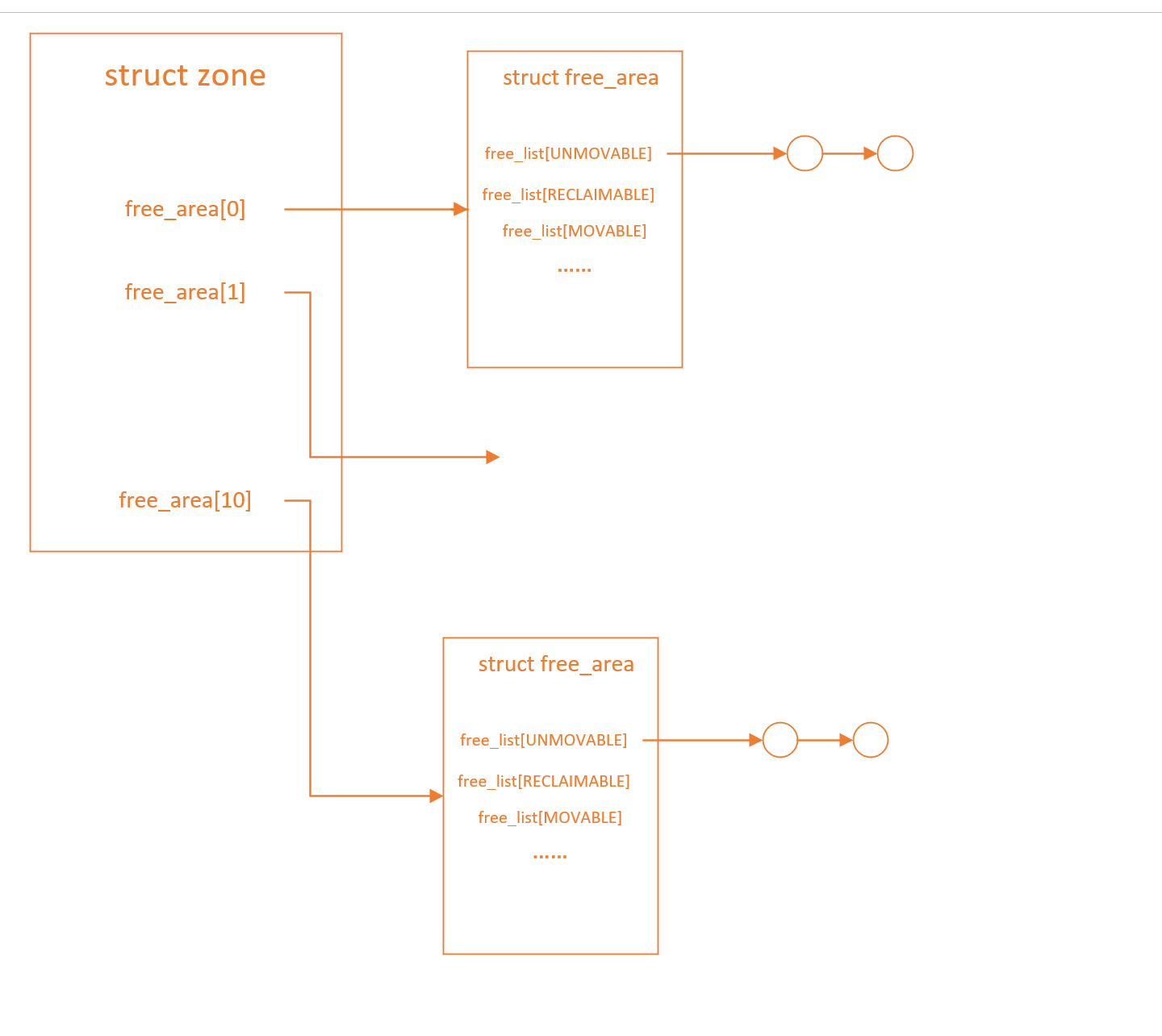
每个管理区zone都有自己的伙伴系统管理属于这个管理区的页框。在一个管理区中,伙伴系统一共维护着包含1,2,4,8,16,…,512,1024个连续页框的链表。
1 2 3 4 5 6 7 8 9 10 #define MAX_ORDER 11 struct zone { struct free_area free_area [MAX_ORDER ]; } struct free_area { struct list_head free_list [MIGRATE_TYPES ]; unsigned long nr_free; }
伙伴系统中,相同大小的连续页框连接形成一个链表,在链表的每个节点中,又有以MIGRATE_TYPES区分的小链表 ,
其MIGRATE_TYPES为页框类型,基本有如下:
MIGRATE_UNMOVABLE: 页框内容不可移动,在内存中位置必须固定,无法移动到其他地方,核心内核分配的大部分页面都属于这一类。MIGRATE_RECLAIMABLE: 页框内容可回收,不能直接移动,但是可以回收,因为还可以从某些源重建页面,比如映射文件的数据属于这种类别,kswapd会按照一定的规则,周期性的回收这类页面。MIGRATE_MOVABLE: 页框内容可移动,属于用户空间应用程序的页属于此类页面,它们是通过页表映射的,因此我们只需要更新页表项,并把数据复制到新位置就可以了,当然要注意,一个页面可能被多个进程共享,对应着多个页表项。MIGRATE_PCPTYPES: 用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目。MIGRATE_CMA: 预留一段的内存给驱动使用,但当驱动不用的时候,伙伴系统可以分配给用户进程用作匿名内存或者页缓存。而当驱动需要使用时,就将进程占用的内存通过回收或者迁移的方式将之前占用的预留内存腾出来,供驱动使用。MIGRATE_ISOLATE: 不能从这个链表分配页框,因为这个链表专门用于NUMA结点移动物理内存页,将物理内存页内容移动到使用这个页最频繁的CPU。
在分配时,可能会出现某种类型的页面被耗尽不满足要求,因此需要如下对不同类型的页框进行优先级定义
1 2 3 4 5 6 7 8 9 10 11 12 static int fallbacks[MIGRATE_TYPES][3 ] = { [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES }, [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, #ifdef CONFIG_CMA [MIGRATE_CMA] = { MIGRATE_TYPES }, #endif #ifdef CONFIG_MEMORY_ISOLATION [MIGRATE_ISOLATE] = { MIGRATE_TYPES }, #endif };
以MIGRATE_RECLAIMABLE为例,如果我需要申请这种页框,当然会优先从这类页框的链表中获取,如果没有,我会依次尝试从MIGRATE_UNMOVABLE -> MIGRATE_MOVABLE -> MIGRATE_RESERVE链进行分配。
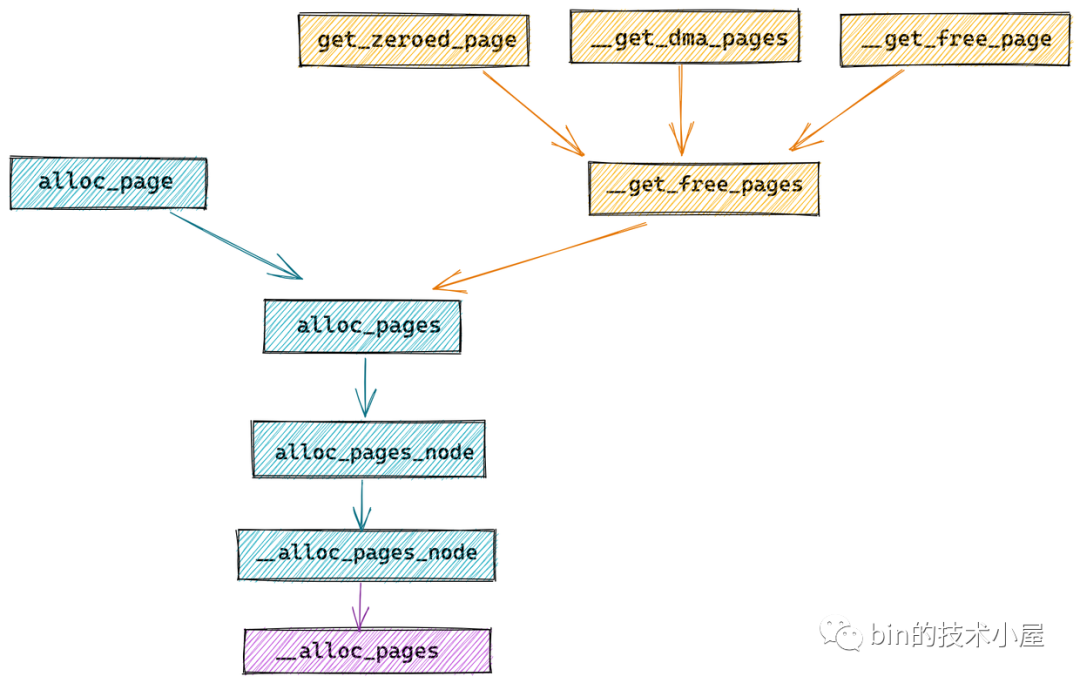
内核物理内存分配 内存分配 1 2 struct page *alloc_pages(gfp_t gfp, unsigned int order); #define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
alloc_pages 函数用于向底层伙伴系统申请 2 的 order 次幂个连续物理内存页组成的内存块,该函数返回值是一个 struct page 类型的指针用于指向申请的内存块中第一个物理内存页 。返回值是页的物理内存地址 ,alloc_page用于分配单个页,其实就是把order指定为0。
1 2 3 4 5 6 7 8 9 unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order){ struct page *page ; page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order); if (!page) return 0 ; return (unsigned long ) page_address(page); }
使用__get_free_pages函数的功能和alloc_pages一样,只是返回的是页的虚拟地址 。在其函数内部就是调用的alloc_pages,并调用page_address把页的物理地址转换成页的虚拟地址。
无论是 alloc_pages 也好还是 `__get_free_pages`` 也好,它们申请到的内存页中包含的数据在一开始都不是空白的,而是内核随机产生的信息 。
内核又提供了一个函数 get_zeroed_page,这个函数会将从伙伴系统中申请到内存页全部初始化填充为 0 ,这在分配物理内存页给用户空间使用 的时候非常有用。
1 2 3 4 unsigned long get_zeroed_page (gfp_t gfp_mask) { return __get_free_pages(gfp_mask | __GFP_ZERO, 0 ); }
内核还提供了一个 __get_dma_pages 函数,专门用于从 DMA 内存区域分配适用于 DMA 的物理内存页。其底层也是依赖于 __get_free_pages 函数。
1 #define __get_dma_pages(gfp_mask, order) __get_free_pages((gfp_mask) | GFP_DMA, (order))
内存释放 1 2 3 4 5 6 void __free_pages(struct page *page, unsigned int order); void free_pages (unsigned long addr, unsigned int order) ; #define __free_page(page) __free_pages((page), 0) #define free_page(addr) free_pages((addr), 0)
规范物理内存分配行为的掩码gfp_mask 在进行物理内存分配的时候,需要对分配行为做出很多的设定与规范,使用gfp_mask掩码来规范。
以下是对掩码的定义,在include/linux/gfp.h中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #define ___GFP_DMA 0x01u #define ___GFP_HIGHMEM 0x02u #define ___GFP_DMA32 0x04u #define ___GFP_MOVABLE 0x08u #define ___GFP_RECLAIMABLE 0x10u #define ___GFP_HIGH 0x20u #define ___GFP_IO 0x40u #define ___GFP_FS 0x80u #define ___GFP_ZERO 0x100u #define ___GFP_ATOMIC 0x200u #define ___GFP_DIRECT_RECLAIM 0x400u #define ___GFP_KSWAPD_RECLAIM 0x800u #define ___GFP_WRITE 0x1000u #define ___GFP_NOWARN 0x2000u #define ___GFP_RETRY_MAYFAIL 0x4000u #define ___GFP_NOFAIL 0x8000u #define ___GFP_NORETRY 0x10000u #define ___GFP_MEMALLOC 0x20000u #define ___GFP_COMP 0x40000u #define ___GFP_NOMEMALLOC 0x80000u #define ___GFP_HARDWALL 0x100000u #define ___GFP_THISNODE 0x200000u #define ___GFP_ACCOUNT 0x400000u #define ___GFP_ZEROTAGS 0x800000u #define ___GFP_SKIP_KASAN_POISON 0x1000000u
将这些宏定义的值转为二进制就看到,每一种占一个bit位。使用掩码的时候做位运算即可
没有zone_normal是因为默认的分配就是zone_normal。
同样在/include/linux/gfp.h中定义了gfp_zone函数,函数返回此次内存分配中的最高的物理内存区域 。较为新的5.14版本中相关代码可读性很差。
在2.6.24版本中,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 static inline enum zone_type gfp_zone (gfp_t flags) { int base = 0 ; #ifdef CONFIG_NUMA if (flags & __GFP_THISNODE) base = MAX_NR_ZONES; #endif #ifdef CONFIG_ZONE_DMA if (flags & __GFP_DMA) return base + ZONE_DMA; #endif #ifdef CONFIG_ZONE_DMA32 if (flags & __GFP_DMA32) return base + ZONE_DMA32; #endif if ((flags & (__GFP_HIGHMEM | __GFP_MOVABLE)) == (__GFP_HIGHMEM | __GFP_MOVABLE)) return base + ZONE_MOVABLE; #ifdef CONFIG_HIGHMEM if (flags & __GFP_HIGHMEM) return base + ZONE_HIGHMEM; #endif return base + ZONE_NORMAL; }
内核将一些常用的gfp_t掩码组合提前准备好了
1 2 3 4 5 6 7 8 9 #define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM) #define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS) #define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM) #define GFP_NOIO (__GFP_RECLAIM) #define GFP_NOFS (__GFP_RECLAIM | __GFP_IO) #define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL) #define GFP_DMA __GFP_DMA #define GFP_DMA32 __GFP_DMA32 #define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
GFP_ATOMIC表示分配行为是原子的,是高优先级的。如果内存空间不够,则会从紧急预留内存中分配。GFP_KERNEL设置之后内核的分配内存行为可能会阻塞睡眠,可以允许内核置换出一些不活跃的内存页到磁盘中。GFP_NOIO 和 GFP_NOFS 分别禁止内核在分配内存时进行磁盘 IO 和 文件系统 IO 操作。GFP_HIGHUSER 用于给用户空间分配高端内存。因为在用户虚拟空间中,都是通过页表来访问非直接映射的高端内存区域
物理内存分配内核源码实现 内存分配行为标识掩码 在内核文件 /mm/internal.h 中定义了影响内核分配行为的标识
1 2 3 4 5 6 7 8 9 10 #define ALLOC_WMARK_MIN WMARK_MIN #define ALLOC_WMARK_LOW WMARK_LOW #define ALLOC_WMARK_HIGH WMARK_HIGH #define ALLOC_NO_WATERMARKS 0x04 #define ALLOC_HARDER 0x10 #define ALLOC_HIGH 0x20 #define ALLOC_CPUSET 0x40 #define ALLOC_KSWAPD 0x800
ALLOC_NO_WATERMARKS: 表示在内存分配过程中完全不会考虑min、low、high三个水位线的影响。ALLOC_WMARK_HIGH: 表示在内存分配的时候,当前物理内存区域 zone 中剩余内存页的数量至少要达到 _watermark[WMARK_HIGH] 水位线,才能进行内存的分配。ALLOC_WMARK_LOW 和 ALLOC_WMARK_MIN 要表达的内存分配语义也是一样,当前物理内存区域 zone 中剩余内存页的数量至少要达到水位线 _watermark[WMARK_LOW] 或者 _watermark[WMARK_MIN],才能进行内存的分配。
ALLOC_HARDER: 表示在内存分配的时候,会放宽内存分配规则的限制,所谓的放宽规则就是降低 _watermark[WMARK_MIN] 水位线,努力使内存分配最大可能成功。ALLOC_HIGH: 当我们在 gfp_t 掩码中设置了 ___GFP_HIGH 时,ALLOC_HIGH 标识才起作用,该标识表示当前内存分配请求是高优先级的,内核急切的需要内存ALLOC_CPUSET: 表示内存只能在当前进程所允许运行的 CPU 所关联的 NUMA 节点中进行分配。ALLOC_KSWAPD: 表示允许唤醒 NUMA 节点中的 KSWAPD 进程,异步进行内存回收。
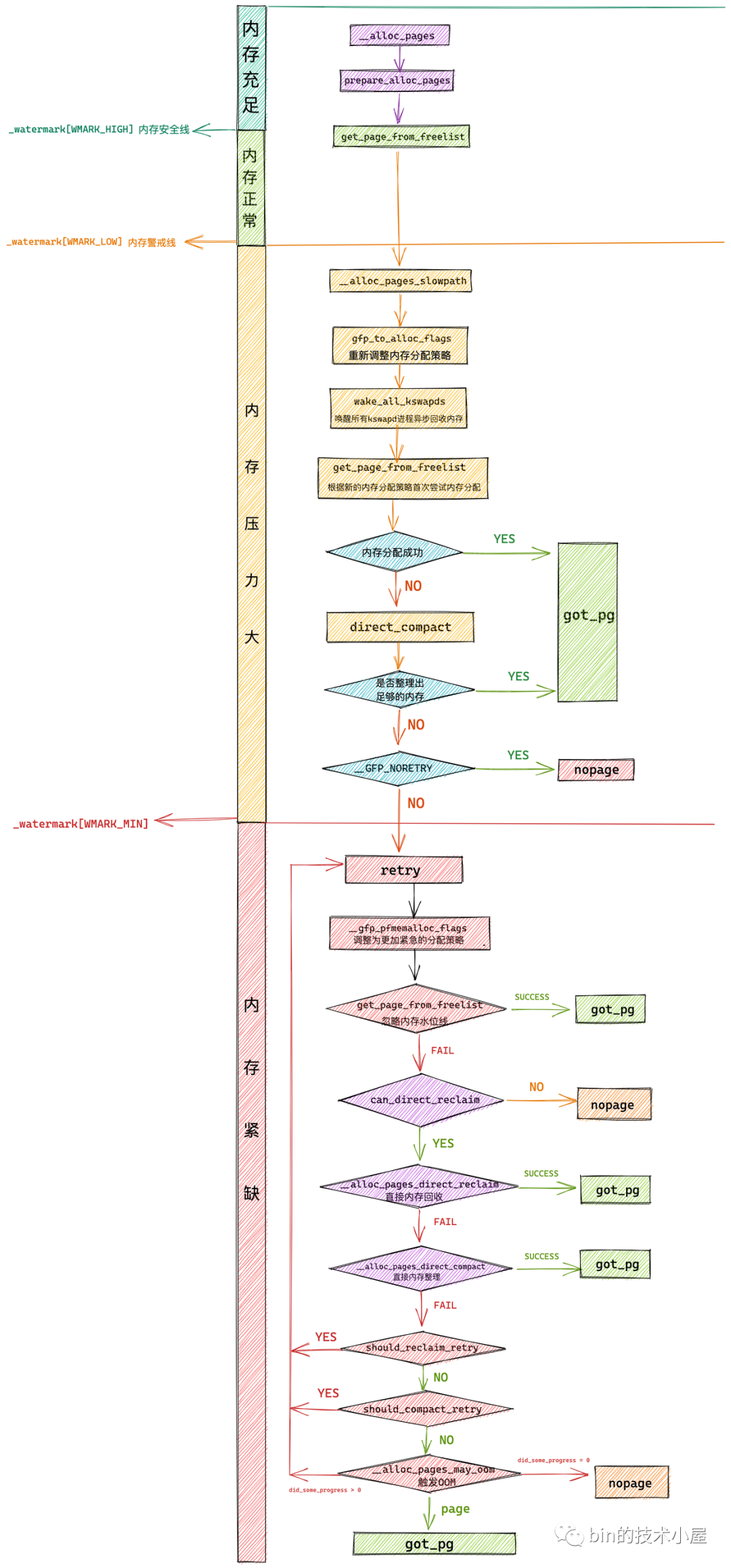
内存分配的心脏 __alloc_pages
内存分配的任务最终会落在 alloc_pages 这个接口函数中,在 alloc_pages 中会调用 alloc_pages_node 进而调用 alloc_pages_node 函数,最终通过 alloc_pages 函数正式进入内核内存分配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 struct page *__alloc_pages (gfp_t gfp , unsigned int order , int preferred_nid , nodemask_t *nodemask ) { struct page *page ; unsigned int alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_gfp; struct alloc_context ac = if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp & __GFP_NOWARN)); return NULL ; } gfp &= gfp_allowed_mask; gfp = current_gfp_context(gfp); alloc_gfp = gfp; if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac, &alloc_gfp, &alloc_flags)) return NULL ; alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp); page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); if (likely(page)) goto out; alloc_gfp = gfp; ac.spread_dirty_pages = false ; ac.nodemask = nodemask; page = __alloc_pages_slowpath(alloc_gfp, order, &ac); out: if (memcg_kmem_enabled() && (gfp & __GFP_ACCOUNT) && page && unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0 )) { __free_pages(page, order); page = NULL ; } trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype); return page; } EXPORT_SYMBOL(__alloc_pages);
上述代码的整体逻辑如下:
首先尝试在内存水位线VMARK_LOW之上进行一次内存分配,对应unsigned int alloc_flags = ALLOC_WMARK_LOW
校验本次内存分配指定伙伴系统的分配阶 order 的有效性,对应if (unlikely(order >= MAX_ORDER))
调用 prepare_alloc_pages 初始化 alloc_context ,用于在不同内存分配辅助函数中传递内存分配参数。为接下来即将进行的快速内存分配做准备。
调用 get_page_from_freelist 方法首次尝试在伙伴系统中进行内存分配
当快速内存分配失败之后,情况就会变得非常复杂,内核将不得不做更多的工作,比如开启 kswapd 进程异步内存回收,更极端的情况则需要进行直接内存回收,或者直接内存整理以获取更多的空闲连续内存。这一切的复杂逻辑全部封装在 __alloc_pages_slowpath 函数中。
整个过程中,有三个重要函数:
prepare_alloc_pages函数用于初始化内存分配策略。
alloc_pages_slowpath函数在初次快速分配失败后,进行慢速分配
get_page_from_freelist函数用于在伙伴系统中进行内存分配。
本次博客先介绍前两个函数
prepare_alloc_pages函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 static inline bool prepare_alloc_pages (gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_gfp, unsigned int *alloc_flags) { ac->highest_zoneidx = gfp_zone(gfp_mask); ac->zonelist = node_zonelist(preferred_nid, gfp_mask); ac->nodemask = nodemask; ac->migratetype = gfp_migratetype(gfp_mask); if (cpusets_enabled()) { *alloc_gfp |= __GFP_HARDWALL; if (in_task() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; } fs_reclaim_acquire(gfp_mask); fs_reclaim_release(gfp_mask); might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM); if (should_fail_alloc_page(gfp_mask, order)) return false ; *alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, *alloc_flags); ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE); ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); return true ; }
prepare_alloc_pages 主要的任务就是在快速内存分配开始之前,做一些准备初始化的工作,其中最核心的就是从指定 NUMA 节点中,根据 gfp_mask 掩码中的内存区域修饰符获取可以进行内存分配的所有内存区域 zone (包括其他备用 NUMA 节点中包含的内存区域)。
alloc_pages_slowpath函数 alloc_pages_slowpath 函数非常的复杂,其中包含了内存分配的各种异常情况的处理,并且会根据前边介绍的 GFP_,ALLOC 等各种内存分配策略掩码进行不同分支的处理,这样就变得非常的庞大而繁杂。
其基本逻辑如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static inline struct page *__alloc_pages_slowpath (gfp_t gfp_mask , unsigned int order , struct alloc_context *ac ) { ......... 初始化慢速内存分配路径下的相关参数 ....... retry_cpuset: ......... 调整内存分配策略 alloc_flags 采用更加激进方式获取内存 ...... ......... 此时内存分配主要是在进程所允许运行的 CPU 相关联的 NUMA 节点上 ...... ......... 内存水位线下调至 WMARK_MIN ........... ......... 唤醒所有 kswapd 进程进行异步内存回收 ........... ......... 触发直接内存整理 direct_compact 来获取更多的连续空闲内存 ...... retry: ......... 进一步调整内存分配策略 alloc_flags 使用更加激进的非常手段进行内存分配 ........... ......... 在内存分配时忽略内存水位线 ........... ......... 触发直接内存回收 direct_reclaim ........... ......... 再次触发直接内存整理 direct_compact ........... ......... 最后的杀手锏触发 OOM 机制 ........... nopage: ......... 经过以上激进的内存分配手段仍然无法满足内存分配就会来到这里 ...... ......... 如果设置了 __GFP_NOFAIL 不允许内存分配失败,则不停重试上述内存分配过程 ...... fail: ......... 内存分配失败,输出告警信息 ........ warn_alloc(gfp_mask, ac->nodemask, "page allocation failure: order:%u" , order); got_pg: ......... 内存分配成功,返回新申请的内存块 ........ return page; }
源代码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 static inline struct page *__alloc_pages_slowpath (gfp_t gfp_mask , unsigned int order , struct alloc_context *ac ) { bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM; const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER; struct page *page =NULL ; unsigned int alloc_flags; unsigned long did_some_progress; enum compact_priority compact_priority ; enum compact_result compact_result ; int compaction_retries; int no_progress_loops; unsigned int cpuset_mems_cookie; unsigned int zonelist_iter_cookie; int reserve_flags; if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) == (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM))) gfp_mask &= ~__GFP_ATOMIC; restart: compaction_retries = 0 ; no_progress_loops = 0 ; compact_priority = DEF_COMPACT_PRIORITY; cpuset_mems_cookie = read_mems_allowed_begin(); zonelist_iter_cookie = zonelist_iter_begin(); alloc_flags = gfp_to_alloc_flags(gfp_mask); ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); if (!ac->preferred_zoneref->zone) goto nopage; if (alloc_flags & ALLOC_KSWAPD) wake_all_kswapds(order, gfp_mask, ac); page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac); if (page) goto got_pg; if (can_direct_reclaim && (costly_order || (order > 0 && ac->migratetype != MIGRATE_MOVABLE)) && !gfp_pfmemalloc_allowed(gfp_mask)) { page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac, INIT_COMPACT_PRIORITY, &compact_result); if (page) goto got_pg; if (costly_order && (gfp_mask & __GFP_NORETRY)) { if (compact_result == COMPACT_SKIPPED || compact_result == COMPACT_DEFERRED) goto nopage; compact_priority = INIT_COMPACT_PRIORITY; } } retry: if (alloc_flags & ALLOC_KSWAPD) wake_all_kswapds(order, gfp_mask, ac); reserve_flags = __gfp_pfmemalloc_flags(gfp_mask); if (reserve_flags) alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, reserve_flags); if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) { ac->nodemask = NULL ; ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); } page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac); if (page) goto got_pg; if (!can_direct_reclaim) goto nopage; if (current->flags & PF_MEMALLOC) goto nopage; page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac, &did_some_progress); if (page) goto got_pg; page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac, compact_priority, &compact_result); if (page) goto got_pg; if (gfp_mask & __GFP_NORETRY) goto nopage; if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL)) goto nopage; if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags, did_some_progress > 0 , &no_progress_loops)) goto retry; if (did_some_progress > 0 && should_compact_retry(ac, order, alloc_flags, compact_result, &compact_priority, &compaction_retries)) goto retry; if (check_retry_cpuset(cpuset_mems_cookie, ac) || check_retry_zonelist(zonelist_iter_cookie)) goto restart; page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress); if (page) goto got_pg; if (tsk_is_oom_victim(current) && (alloc_flags & ALLOC_OOM || (gfp_mask & __GFP_NOMEMALLOC))) goto nopage; if (did_some_progress) { no_progress_loops = 0 ; goto retry; } nopage: if (check_retry_cpuset(cpuset_mems_cookie, ac) || check_retry_zonelist(zonelist_iter_cookie)) goto restart; if (gfp_mask & __GFP_NOFAIL) { if (WARN_ON_ONCE(!can_direct_reclaim)) goto fail; WARN_ON_ONCE(current->flags & PF_MEMALLOC); WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER); page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac); if (page) goto got_pg; cond_resched(); goto retry; } fail: warn_alloc(gfp_mask, ac->nodemask, "page allocation failure: order:%u" , order); got_pg: return page; } static inline bool prepare_alloc_pages (gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_gfp, unsigned int *alloc_flags) { ac->highest_zoneidx = gfp_zone(gfp_mask); ac->zonelist = node_zonelist(preferred_nid, gfp_mask); ac->nodemask = nodemask; ac->migratetype = gfp_migratetype(gfp_mask); if (cpusets_enabled()) { *alloc_gfp |= __GFP_HARDWALL; if (in_task() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; } fs_reclaim_acquire(gfp_mask); fs_reclaim_release(gfp_mask); might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM); if (should_fail_alloc_page(gfp_mask, order)) return false ; *alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, *alloc_flags); ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE); ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); return true ; }
其中相关的几个函数:
gfp_to_alloc_flags函数更改分配策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 static inline unsigned int gfp_to_alloc_flags (gfp_t gfp_mask) { unsigned int alloc_flags = ALLOC_WMARK_MIN | ALLOC_CPUSET; BUILD_BUG_ON(__GFP_HIGH != (__force gfp_t ) ALLOC_HIGH); BUILD_BUG_ON(__GFP_KSWAPD_RECLAIM != (__force gfp_t ) ALLOC_KSWAPD); alloc_flags |= (__force int ) (gfp_mask & (__GFP_HIGH | __GFP_KSWAPD_RECLAIM)); if (gfp_mask & __GFP_ATOMIC) { if (!(gfp_mask & __GFP_NOMEMALLOC)) alloc_flags |= ALLOC_HARDER; alloc_flags &= ~ALLOC_CPUSET; } else if (unlikely(rt_task(current)) && in_task()) alloc_flags |= ALLOC_HARDER; alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, alloc_flags); return alloc_flags; }
__gfp_pfmemalloc_flags函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static inline int __gfp_pfmemalloc_flags(gfp_t gfp_mask){ if (unlikely(gfp_mask & __GFP_NOMEMALLOC)) return 0 ; if (gfp_mask & __GFP_MEMALLOC) return ALLOC_NO_WATERMARKS; if (in_serving_softirq() && (current->flags & PF_MEMALLOC)) return ALLOC_NO_WATERMARKS; if (!in_interrupt()) { if (current->flags & PF_MEMALLOC) return ALLOC_NO_WATERMARKS; else if (oom_reserves_allowed(current)) return ALLOC_OOM; } return 0 ; }
内存分配流程图: